利用Skill将Apple Books高亮同步到Obsidian

1. 一个烦人的重复劳动
我一直在 iPad 上用 Apple Books 看书,边看边划高亮、随手写点评。这些笔记散落在图书 App 里,没有和我的 Obsidian 知识库打通。
之前也用过一些第三方工具导出 Apple Books 笔记,但要么收费、要么需要 iCloud 中转、要么格式不对胃口。Obsidian 那边我已经搭好了「读书卡片」系统——用 DataviewJS 做的瀑布流卡片,配合 mood 色系区分,比 Notion 的 Gallery View 还灵活。
于是我一直手动搬运——打开 Apple Books → 逐条复制高亮 → 切到 Obsidian → 粘贴到新卡片 → 填 book_key → 填日期。一本书几十条高亮,重复几十次。
直到这周,我决定花一个下午来解决这件事。
2. 打开 Apple Books 的 SQLite 数据库
Apple Books 的数据存在本地的 SQLite 里:
1 | ~/Library/Containers/com.apple.iBooksX/Data/Documents/ |
打开一看,356 条高亮,12 本书,结构很清晰:
1 | CREATE TABLE ZAEANNOTATION ( |
书的元数据在另一个库:
1 | BKLibrary/BKLibrary-1-091020131601.sqlite |
2.1. 那些我以为有但实际上没有的字段
查库的过程有几个意外。
页码 — ZPLABSOLUTEPHYSICALLOCATION 字段,356 条记录中只有 1 条有值(64),其余全是 0。Apple Books 的 SQLite 层根本不存页码。这在技术上可以理解——EPUB 是流式排版,同一本书在不同设备上的「页」不同,物理页码没有意义。
章节 — ZANNOTATIONLOCATION 存的是 epubcfi 字符串(EPUB Canonical Fragment Identifier),形如:
1 | epubcfi(/6/24[id73]!/4/18/1,:9,:31) |
有的书能提取出 ch7、x_chapter_00006_xhtml 这种可读标识,但大部分是 id73、id00001 这种出版 ID,还有 150 多条完全没有章节字段。覆盖率太低——解析成本远高于收益,最终决定不提取。
修改时间 — ZANNOTATIONMODIFICATIONDATE 倒是每个都有,但跟创建时间的差异通常只有几秒,没有独立价值。
最终可用的字段只有四个:asset_id、高亮原文、点评、创建时间。足够了——图书条目有书名和作者,高亮有原文和笔记,加上创建时间可以排序。四个字段撑起了一整套读书笔记同步系统。
3. Skill 设计:让同步逻辑成为可复用的 AI 指令
这次我不只是想写一个一次性脚本。我想要一个以后随时能用的能力——说一句「同步 Apple Books 高亮到 KnowledgeOS」,AI 就知道怎么干活、去哪找数据、用什么模板输出。
在 Hermes Agent 里,这个能力叫 skill。
3.1. Skill 的三层结构
这个 skill 由三部分组成:
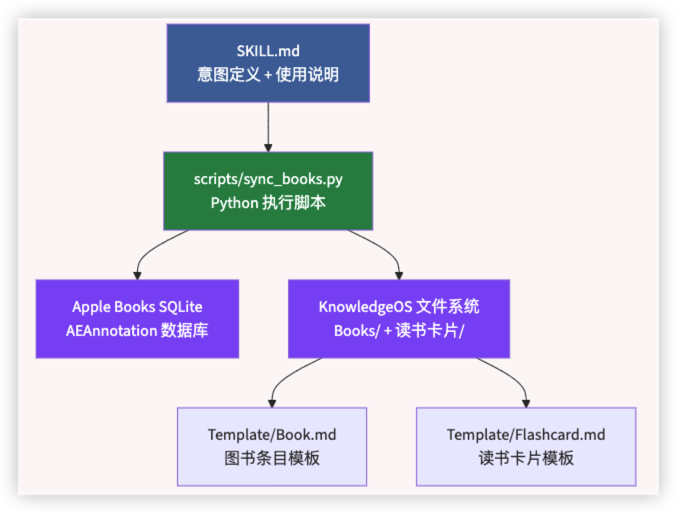
SKILL.md 负责告诉 AI:「这个 skill 解决什么问题、什么时候用、怎么调用脚本、输出是什么格式」。它不包含执行逻辑——执行逻辑在脚本里。它不包含模板——模板数据在 KnowledgeOS 本身。它只做一件事:让 AI 理解上下文和约束,避免猜错。
scripts/sync_books.py 是真正的执行者。它读取 SQLite、解析数据、生成符合模板格式的 Markdown 文件。
模板(Book.md / Flashcard.md) 在 KnowledgeOS 中,由用户自己维护。skill 不复制模板内容,只保证输出的文件格式与模板一致。这是沿用了我之前在测试工作流中的设计原则——单一真相来源。
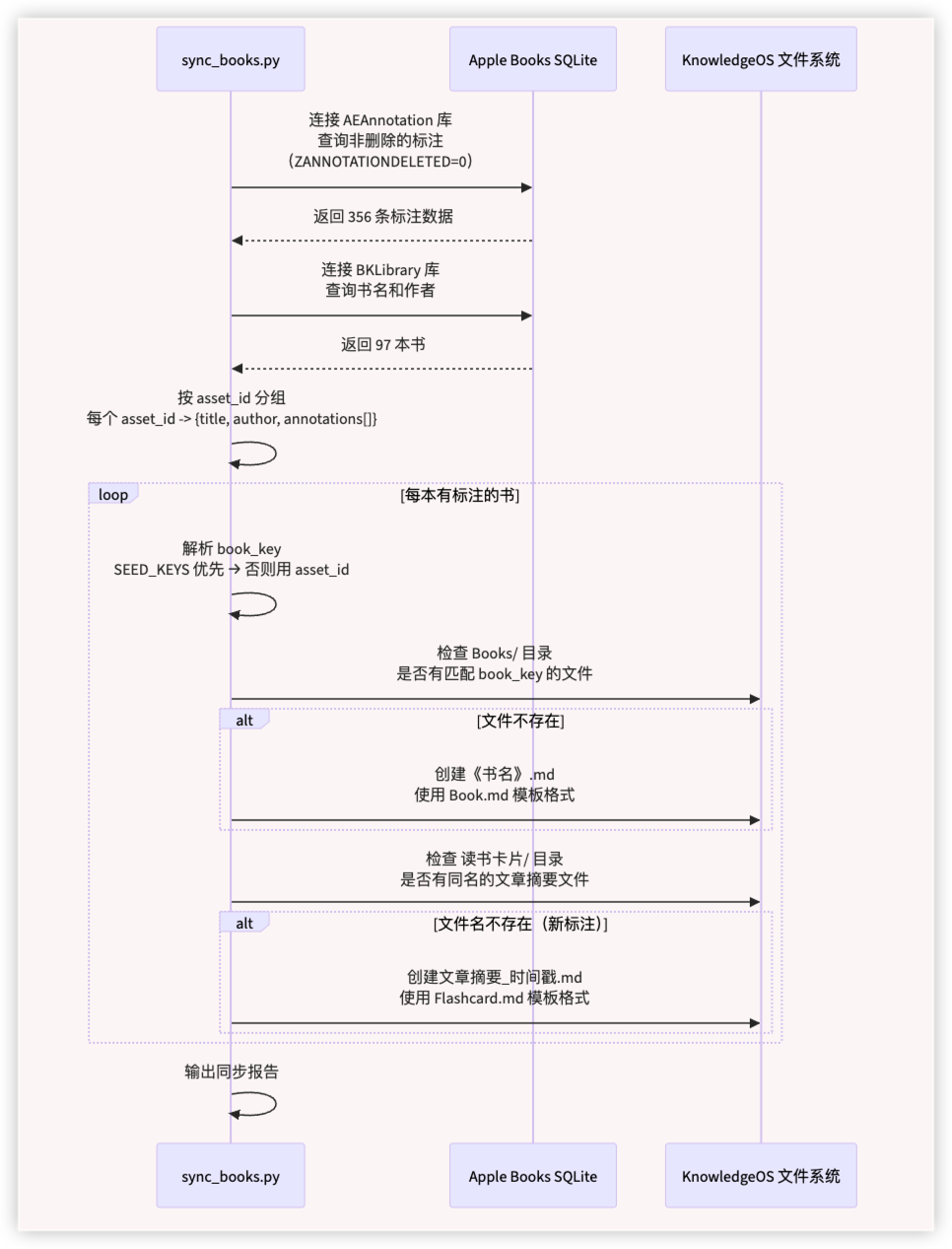
3.2. 脚本的核心流程
Python 脚本的完整数据流如下:
3.3. 核心代码解析
去重逻辑是整个脚本的基石。最终版本采用两层去重:
1 | # 第一层:文件名去重(快速路径) |
文件名去重基于高亮创建时间——Apple Books 的时间戳精确到秒,而实际操作中不太可能在同一秒内创建两条不同的高亮(即使有,后续的内容去重层也会兜住)。
模板渲染用了最朴素的字符串替换,没有引入 Jinja2 等模板引擎:
1 | def _render_card(created, book_key, quote, book_ref, insight): |
选择字符串替换而非模板引擎的理由很简单:依赖越少越稳定。这个脚本要跑在很多可能没有 Jinja2 的 Python 环境里(macOS 自带 Python、Hermes 沙箱等),str.replace 在任何地方都能正常工作。
book_key 决定逻辑是脚本中最关键的设计决策:
1 | # SEED_KEYS 记录了用户已有的自定义 book_key |
asset_id 作为 book_key 的稳定性远超人工设计的 slug——它不会因为用户重命名文件、修改标题、迁移目录而改变。这就是「用数据源的 ID 做主键」这个数据库设计原则在文件系统层面的应用。
4. 迭代:好的设计是从坑里爬出来的
第一版脚本只花了 30 分钟写完。后面修 bug 和调整设计花了 4 个小时。
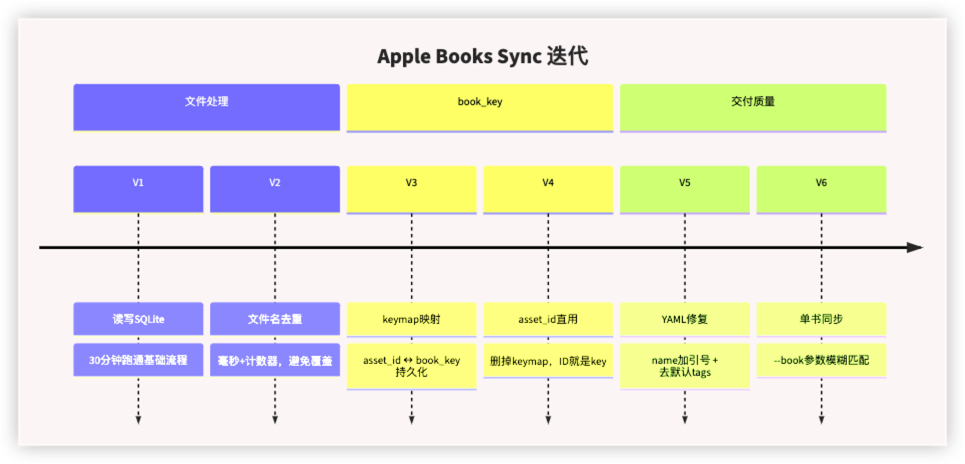
脚本在文件命名时用 datetime.now() 做时间戳。一秒内创建 224 张卡片,后者覆盖前者——最终只有 1 张卡片幸存。
修复方案经历了三次迭代:
1 | V1: 文章摘要_2026-05-21-14-46-35.md ← 秒级,冲突 |
最终版本用高亮在 Apple Books 中的实际创建时间作为文件名。同一个高亮下次重跑同名,直接跳过。这不仅解决了冲突——还顺便实现了增量同步。
4.1. book_key 的三种方案
| 方案 | 优点 | 缺点 | 结论 |
|---|---|---|---|
| 人工 slug(distriction) | 可读性好 | 不能覆盖所有书 | 仅用于已存在的书 |
| 随机 key(book_xxxx) | 唯一性保证 | 需要 keymap 文件持久化 | 冗余 |
| asset_id | 唯一、稳定、零维护 | 不易读 | 最终方案 |
当发现 asset_id 的存在时,前面两个方案都成了过渡方案。它在 Apple Books 内部就是主键,我们拿来当 book_key 直接复用,不需要任何映射或生成逻辑。
4.2. YAML 里的隐形成本
书名 Feeling Great: The Revolutionary New Treatment for Depression and Anxiety 里的英文冒号 + 空格在 YAML 里是 key-value 分隔符。模板写的是:
1 | name: __TITLE__ |
替换后变成:
1 | name: Feeling Great: The Revolutionary New Treatment for Depression and Anxiety |
这不是一个一眼能看出的问题——文件名正常、内容正常、Obsidian 也不报错——直到 Obsidian 的 frontmatter 解析器在 : 处截断,把后半截当成嵌套 key。
修复:
1 | name: "__TITLE__" # 加引号,YAML 将整个值视为字符串 |
同时,quote 和 insight 字段做了双重转义:
1 | quote.replace("\\", "\\\\").replace('"', '\\"') |
第一遍转义反斜杠,第二遍转义双引号。顺序不能错——如果先转义双引号,会把已转义的反斜杠当成新的转义符。
5. 最终方案的数据流
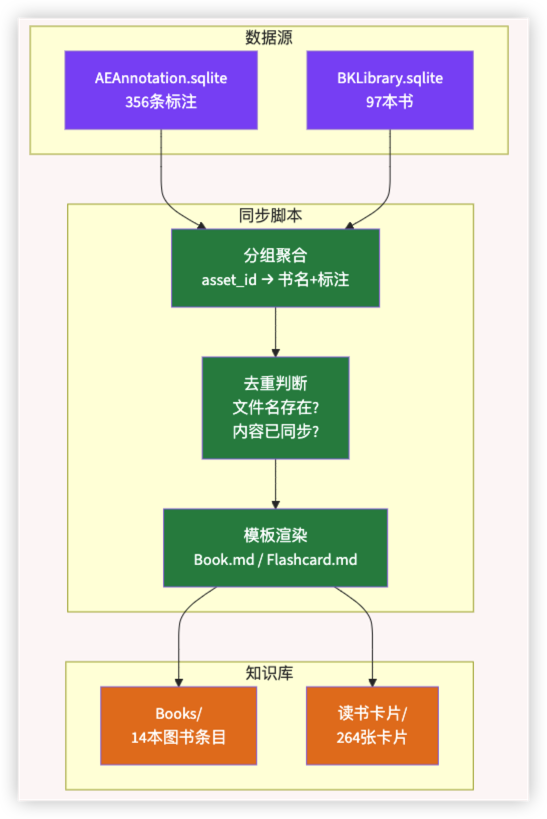
执行一次全量同步:0 张新卡、0 本新书,因为所有高亮都已经同步过了。增量更新的场景是:你在 Apple Books 里新划了一条高亮 → 下次同步发现文件名不存在 → 创建新卡片。
6. 关于 Skill 设计的一个观察
这次做 apple-books-sync skill 的过程和我之前在测试工作流里构建 test-case-writing、testcase-pipeline 的思路很像——只是在不同的领域重复了同一个模式。
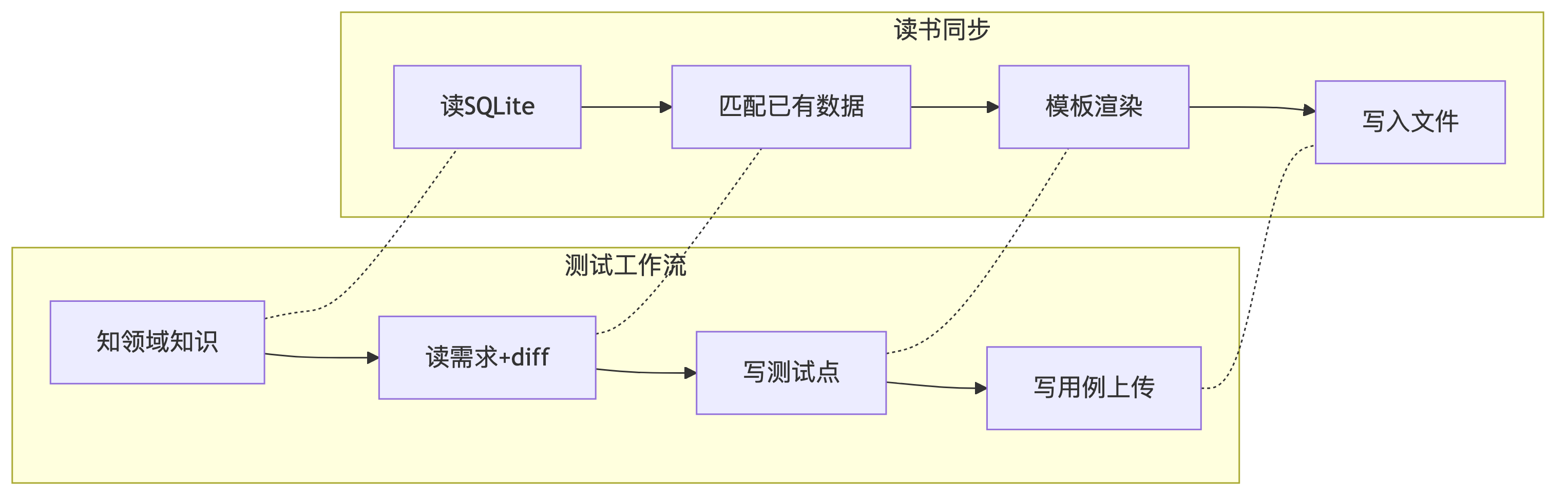
这个模式是:理解数据 → 匹配已有状态 → 按模板输出 → 写入目标位置。不管处理的是测试用例还是读书笔记,骨架都一样。
而 skill 的价值不是约束 AI 的行为——skill 的价值是让 AI 不需要每次重新推断该怎么做。SQLite 路径在哪里、模板有什么格式要求、book_key 怎么确定、YAML 冒号需要转义——这些细节写进 skill 一次,AI 每次执行都能读到,不必再猜。
这半天里我更新了 SKILL.md 大概 8 次——每次用户反馈一个问题,我就在脚本里修一个坑,在 SKILL.md 里补一条说明。Skill 的成熟度,等于你踩过的坑数。
6.1. 使用方式
Skill 设计的目标是让 AI 理解你的意图,不需要记住命令参数。安装后只需对 Hermes Agent 说一句话:
1 | "帮我同步 Apple Books 的高亮到 KnowledgeOS" |
Agent 会自动加载 apple-books-sync skill、读取 SKILL.md 中的上下文说明、调用 Python 脚本、并选择 --book 参数或全量模式。你不需要记住脚本路径、参数名或 SQLite 数据库的位置——这些细节都在 skill 的定义里。
如果想单独跑脚本做调试,当然也可以直接调用:
1 | python3 ~/.hermes/skills/apple/apple-books-sync/scripts/sync_books.py --book 解忧杂货店 |
但日常使用中,你只需要说一句话。
如果你也在用 Obsidian 管理读书笔记,并且手头不止一个设备在阅读,Apple Books 的本地 SQLite 是一个未被充分利用的数据源。它不复杂——一个数据库、两张表、四个字段——但足够支撑一套自动化的读书笔记同步体系。
