agent-next:把测试 Agent 接进流水线——工作流、门禁与 Lazy Load 的 Harness 实践

1. 引子
你大概已经试过:把缺陷管理系统里的 Bug 链接丢给 Agent,让它「帮忙回归一下」。十分钟后它交上来一份像模像样的测试用例,步骤清晰、预期明确——但你不敢直接用。
因为你不知道它有没有读过修复 MR;不知道用例标题里是业务语言还是接口参数字段名;不知道它有没有在共享测试环境上偷偷跑过 curl;更不知道这份 Markdown 是模板产物,还是模型凭记忆「手写」的——而后者往往过不了你们内部的格式校验。
核心矛盾和 UI 生成、内容审核类 Agent 惊人地相似:
| 阶段 | 测试 Agent 的对应表现 |
|---|---|
| 能生成 | 能写用例、能写报告、能复述需求 |
| 不敢上线 | 产物路径乱、阶段乱跳、副作用不可控、无法复现 |
| 中间差什么 | Harness:路由、阶段、证据、门禁、确认 |
本文介绍 agent-next——我们在复杂 B 端系统测试中长期迭代的一套 Harness 工程。它不是「更大的 Prompt」,而是 可版本化、可机器校验、可跨 Cursor / Hermes 复用 的仓库结构。其他行业的测试同事可以只替换 knowledge/ 和 workflow 表头,保留骨架。
2. 背景:为什么「一个大 Skill + 长对话」会失败
2.1. 三类高频任务,一套动作,不同阶段
| 任务类型 | 典型入口 | 若混用同一 Prompt 会怎样 |
|---|---|---|
| 特性测试 | PRD、需求单、特性 MR | 容易跳过需求澄清直接写用例 |
| Bug 回归 | Bug ID、修复 commit、「帮我在浏览器验一下」 | 用户一句「验证」就跳到执行阶段 |
| 发布验收 | 版本号、tag、环境、全量回归窗口 | 范围未锁就做自动化 |
三类任务共享下游能力(读代码、写用例、匹配自动化、执行、写报告),但 阶段顺序与准入证据不同。Harness 的第一职责就是把入口拆开。
2.2. 真实踩坑:一次 Bug 回归的失败路径
某次禅道 Bug #1649 回归,Agent 的实际轨迹是:
1 | 用户:回归 bug 1649 |
对照表:
| Harness 缺失点 | 具体后果 |
|---|---|
| 无阶段门禁 | 用户说「验浏览器」就直奔 Execution |
| 无模板强制 | 无 YAML frontmatter,校验脚本直接失败 |
| 无路径约定 | 运行态目录与交付物目录混用 |
| 无机器校验 | 格式问题靠人眼最后才发现 |
| 上下文膨胀 | 整本 workflow 塞进会话,关键规则被「读不全」 |
设计原则由此固定:规则进仓库、进工具、进门禁;事故教训不写进个人 MEMORY 了事。
3. agent-next 是什么:仓库即 Harness
agent-next 是一个 以 Git 仓库为载体的测试 Agent 操作系统。模型是可替换的;Harness 是团队资产。
一句话分工:
Router 指路,Workflow 定阶段,Skill 承载专长,Knowledge 解释领域,Tool 执行门禁。
3.1. 设计目标
- 默认上下文 尽量小:Router + 当前阶段一篇
phases/*.md。 - 任务 必须先选 workflow entry,再允许写产物。
- Skill 按阶段加载,且
skill_receipts[]记录路径与 sha256(证明真的读过)。 - 源码证据走本地
repositories/dev、test、tools镜像,少猜远程。 - 领域知识在
knowledge/,与「本次 MR / 缺陷单」等来源证据分离。 - 运行记忆落在
runs/<run-id>/state.json,不依赖聊天上下文。 - 缺陷系统写入、共享环境执行、数据注入、SSH、部署、远程仓库写操作 须用户确认。
3.2. 明确不做的事
- 不把全流程塞进一个五千行 Skill。
- 不把用例/报告等交付物当源码配置提交进 Git。
- 不让 Agent 从服务名/README 猜 API 路径——须从用户 curl 或浏览器 Network 追踪。
- 不做「单轮对话轨迹自动写回 Skill」的 Online 自进化(见第 8 节)。
3.3. 仓库目录结构
agent-next 把 Harness 落在 一个 Git 仓库里。目录按五层职责划分;Agent 默认只读入口层 + 当前流程层 + 本阶段技能层,其余按需打开。
1 | agent-next/ |
目录与五层 Harness 的对应关系:
| 目录 / 文件 | Harness 层级 | Agent 典型读法 |
|---|---|---|
AGENTS.md、skills/agent-next/ |
① 入口层 | 每任务首轮 |
workflows/index.md、<entry>/README.md、<entry>/phases/*.md、stage-gates.md |
② 流程层 | index + README 各一次;每阶段只读一篇 phase |
skills/epvs-*/SKILL.md 与 references/ |
③ 技能层 | 仅当前 phase 声明的 Skill |
runs/、outputs/、repositories/、knowledge/ |
④ 证据层 | 写 state / 取证 / 写产物 / 查领域时 |
tools/、templates/、schemas/ |
⑤ 机器层 | 通过 CLI 调用,不全文塞进上下文 |
tools/ 核心脚本(其余为辅助校验或知识维护):
| 脚本 | 作用 |
|---|---|
run_state.py |
创建与更新 runs/<run-id>/state.json |
phase_doc.py |
解析当前阶段 md 路径;--list-phases 列全表 |
phases.py |
阶段名权威列表(与 stage_gate.py 共用) |
copy_template.py |
从 templates/ 生成带 frontmatter 的产物 |
stage_gate.py |
当前 phase 能否标记完成 |
validate_artifact.py / validate_test_cases.py |
产物格式机审 |
validate_run_state.py |
state 字段与 schema 校验 |
边界说明(fork 时建议保留):
runs/与outputs/分离:前者是运行记忆与 gate 记录,后者是给人审的交付物;混用是 Bug #1649 类事故的高频根因。repositories/不进 Git:放被测系统与自动化工程的本地 clone;路径由config/projects.yaml解析。knowledge/可整棵替换:保留_index.md+related[].path跳转约定即可;业务无关的 epvs 内容换成你们自己的术语与页面说明。- 权威来源:阶段顺序以
tools/phases.py为准;过关以tools/stage_gate.py为准;文档与代码冲突时 以代码为准(详见仓库docs/design.md的 Source Of Truth 表)。
4. 五层 Harness 架构(展开说明)
4.1. 总览图
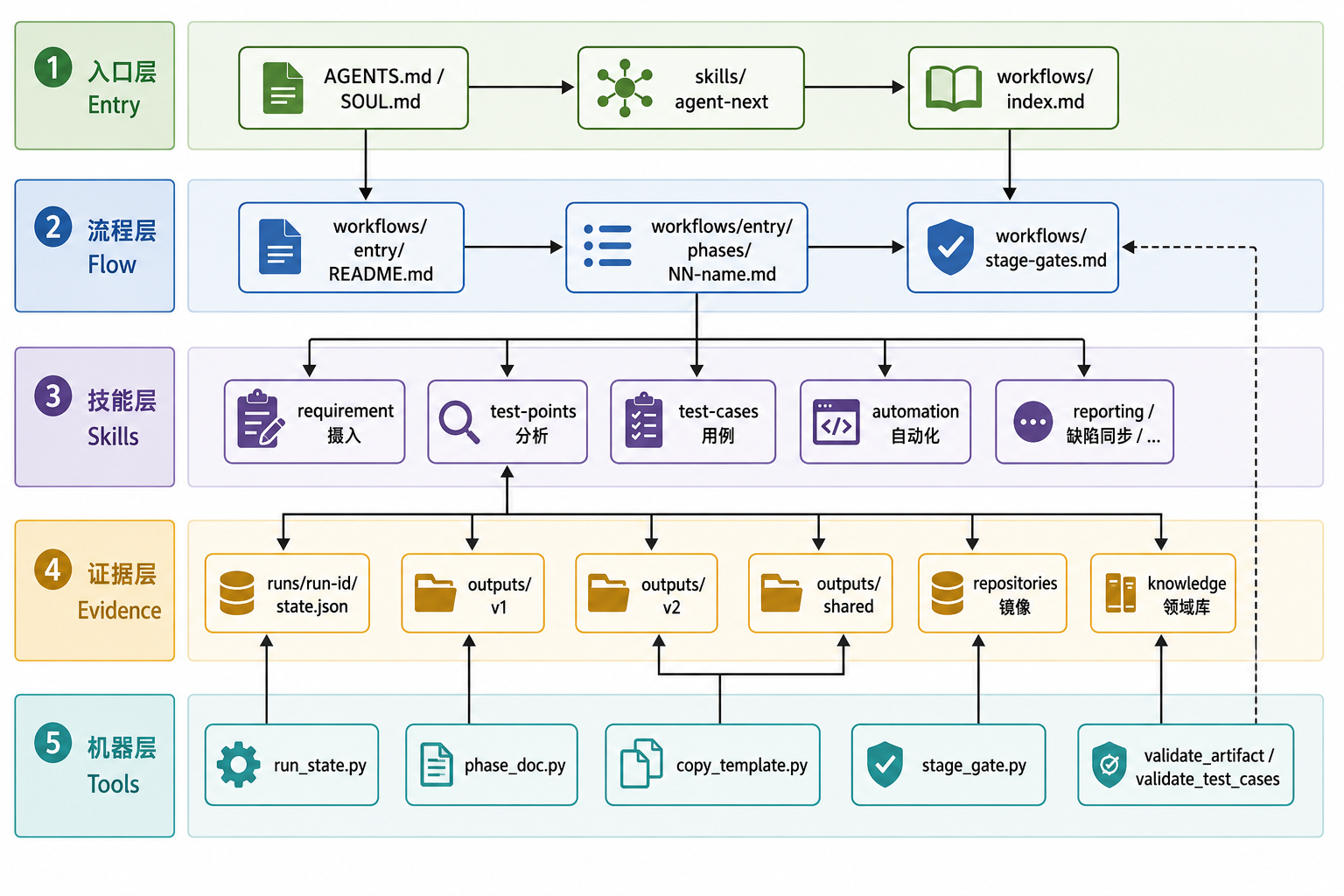
说明:Mermaid 节点里避免使用
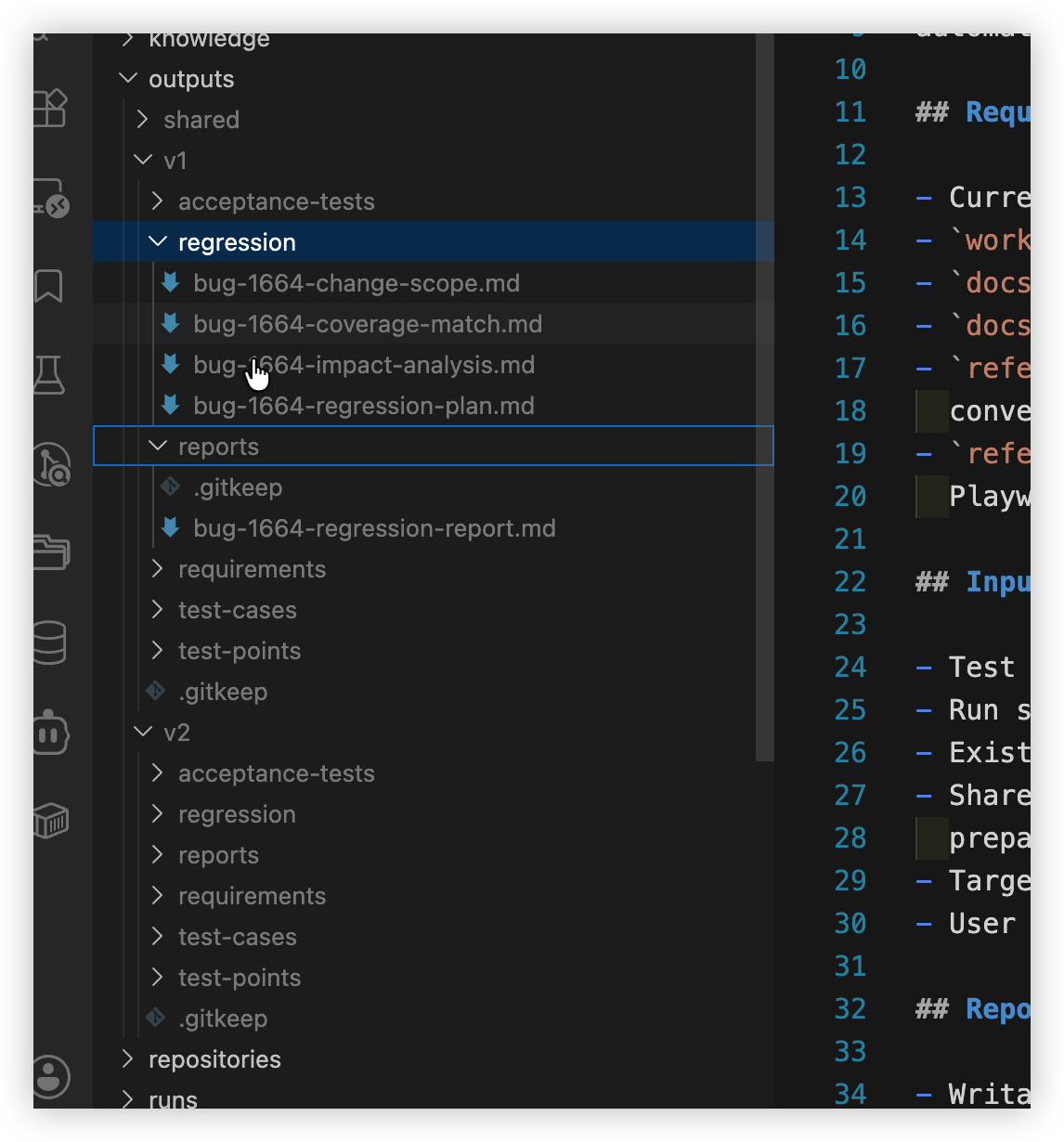
|等特殊字符;产物目录在实现上分为v1、v2、shared三棵输出树。
4.2. ① 入口层:谁在第一屏被加载?
| 组件 | 物理位置 | 作用 |
|---|---|---|
| 硬约束 | 仓库 AGENTS.md |
Cursor 等工作区自动注入 |
| 会话硬约束 | Hermes SOUL.md |
每个新会话注入;不会读 profile 里的 AGENTS |
| Router Skill | skills/agent-next/SKILL.md(约 70 行) |
选 entry、声明 phase、指向 phase_doc |
| 路由索引 | workflows/index.md |
三入口 + Skill 索引 + 首次动作清单 |
关键设计:Router 极薄。它不写用例、不上传缺陷系统、不跑自动化——只做调度与停损(gate 失败即停)。
4.3. ② 流程层:阶段即文件
每个 entry 对应一个目录:
1 | workflows/bug-regression/ |
Lazy Load 解析器(机器可查路径,避免 Agent 猜文件名):
1 | python3 tools/phase_doc.py --entry bug-regression --phase "Change Scope" |
阶段名称的 唯一权威 在 tools/phases.py,与 stage_gate.py 共用同一列表——文档与代码不一致时,以代码为准。
workflows/stage-gates.md 保留 Machine Rules By Phase 表;人类可读的长散文已压缩,避免与机器规则三重重复。
4.4. ③ 技能层:窄 Skill + references
Router 之外是一组 按职能拆分的 Skill(仓库目录名带项目前缀,文中按职能称呼即可):
| 职能 Skill | 负责什么 | Bug 回归典型阶段 |
|---|---|---|
| 需求/缺陷摄入 | 读 PRD、需求单、Bug 单 | Bug Intake |
| 测试点/影响分析 | 变更范围、风险、影响面 | Change Scope、Impact |
| 测试用例 | 用例设计、覆盖匹配 | Coverage Match、补用例 |
| 自动化 | 分类、生成、执行计划 | Decision 之后可选 |
| 报告 | 结项、追溯 | Regression Report |
| 缺陷同步 | 写回缺陷系统(须确认) | 可选 |
格式细则不进 Router,而在 skills/*/references/——例如用例标题必须用 TC-001:业务描述,禁止 VC-01、禁止把 API 字段名当标题。写产物前 强制先读 reference,并记入 knowledge_used。
4.5. ④ 证据层:三类数据,三种用途
1 | runs/<run-id>/ ← 仅运行态(state.json、gate 记录) |
Run State 核心字段(节选):
| 字段 | 含义 | 门禁为何关心 |
|---|---|---|
entry / phase |
当前 workflow 位置 | 防止跳阶段 |
workflow |
如 workflows/bug-regression/README.md |
审计用的索引路径 |
product_line |
v1 或 v2 等产品线标识 |
决定 outputs 子树 |
skill_receipts[] |
读过哪个 SKILL.md + sha256 | 防止「声称加载未加载」 |
repository_evidence[] |
看过哪些文件/commit | 防止空口分析 |
knowledge_used[] |
用过哪些知识页 | 与 knowledge_not_applicable: 二选一 |
artifacts[] |
产物路径、类型、产出阶段 | 与磁盘文件、模板校验联动 |
notes[] |
bug_intake:、decision_path: 等前缀 |
结构化 intake / 决策 |
confirmations[] |
副作用是否已确认 | 阻断未授权操作 |
4.6. ⑤ 机器层:把「应该」变成「能不能过」
| 工具 | 输入 | 输出/效果 |
|---|---|---|
run_state.py |
CLI 参数 | 更新 state.json;--entry 可自动填 workflow README 路径 |
phase_doc.py |
entry + phase | 打印当前阶段 md 路径;--list-phases 列全表 |
copy_template.py |
模板名 + 目标路径 | 带 frontmatter 的合规 Markdown 骨架 |
validate_test_cases.py |
用例文件 | 标题、章节、receipt 等机审 |
validate_artifact.py |
其他模板产物 | frontmatter + section 标记 |
stage_gate.py |
state.json |
当前 phase 能否标记完成;失败打印缺什么 |
半监督闭环(与 UI 自动化生产实践同构):
1 | Agent 生成 → copy_template → validate_*(机审)→ 人审关键节点 → stage_gate(阶段机审) |
4.7. 一次阶段推进的数据流(Bug 回归示例)
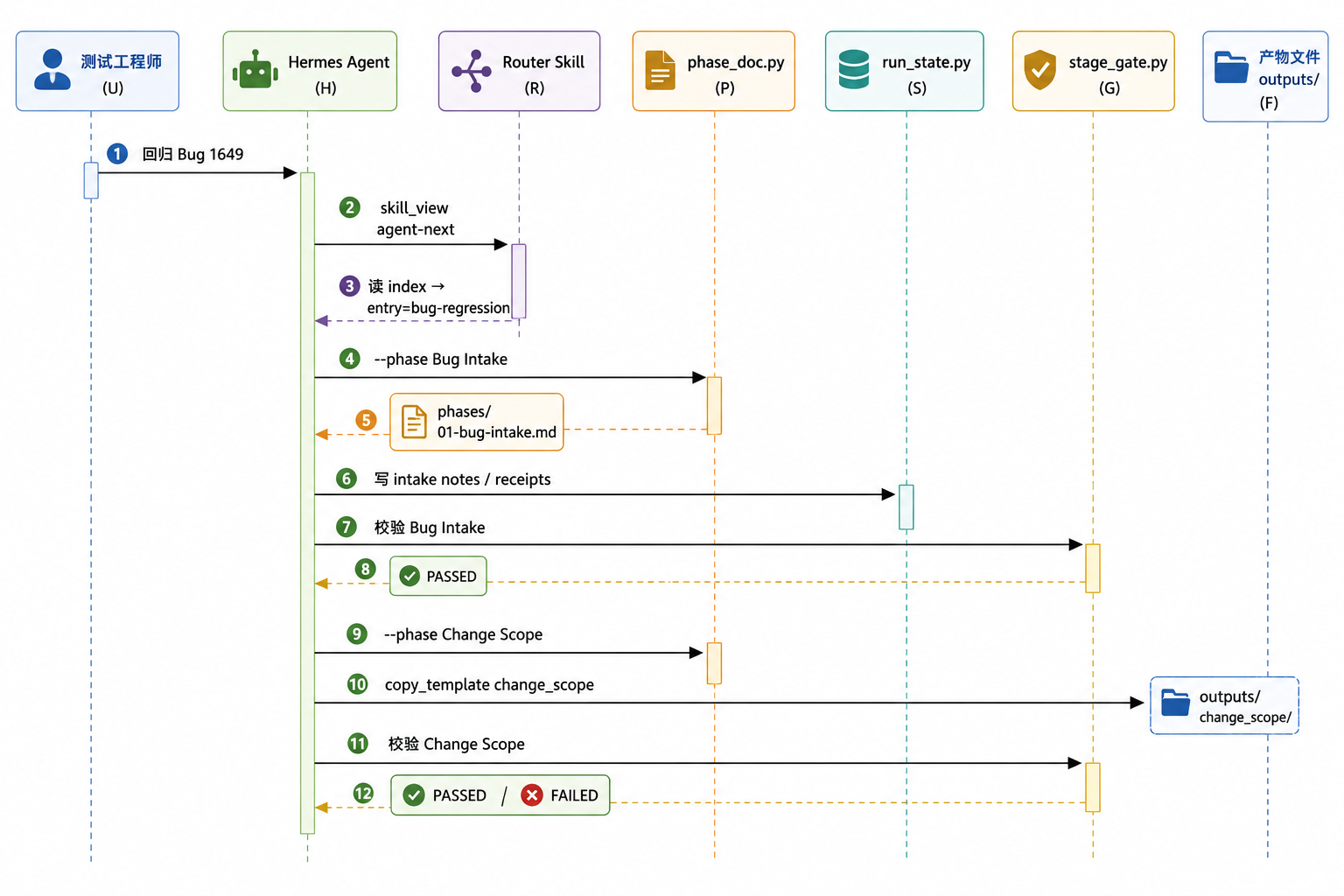
执行log:
1 | ──────────────────────────────────────── |
5. 三条 Workflow 与 Bug 回归阶段(可照抄结构)
5.1. 三个 Entry
| Entry | 何时用 | 阶段数 |
|---|---|---|
feature-testing |
PRD、需求单、特性 MR | 8(含 Optional) |
bug-regression |
Bug ID、修复 MR、回归请求 | 8 |
release-acceptance |
版本、tag、发布验收 | 6 |
5.2. Bug 回归八阶段(目标 / 产出)
| 阶段 | 目标 | 关键产出 |
|---|---|---|
| Bug Intake | 锁定缺陷上下文与修复来源 | bug_intake:、bug_surface:(无 artifact 文件) |
| Change Scope | 弄清改了什么 | change_scope 模板文件 |
| Impact Analysis | 影响面与回归风险 | risk_analysis |
| Coverage Match | 现有覆盖与缺口 | coverage_match |
| Decision Gate | 选执行路径 | decision_path: |
| Regression Plan | 策略与补用例计划 | regression_plan、可选 test_cases |
| Execution | 执行(可选) | execution_record 或 skip 说明 |
| Regression Report | 结项 | regression_report |
交付物路由(bug_surface 决定根目录):
| bug_surface | 输出根目录 | 典型场景 |
|---|---|---|
frontend |
outputs/v1 或 outputs/v2 |
与 product_line 对齐的前端缺陷 |
backend |
outputs/shared |
接口、服务、数据层 |
other |
outputs/shared |
基础设施、跨端、难归类 |
5.3. Lazy Load 带来的上下文收益
| 读法 | 约 Markdown 行数(Bug 回归 @ Change Scope) |
|---|---|
| 旧:单文件 workflow + 长篇 gate 散文 | 400+ |
| 新:README + 单 phase + stage-gates 机器表 | ~100 |
哲学与「知识先编译、再按需读取」一致:不要把手册全文每轮塞进上下文。
6. Skill 自进化:离线归并,而非在线堆 MEMORY
企业场景里,单轮轨迹直接写回 Skill 容易过拟合、越改越臃肿(与 Trace2Skill 等方案指出的单轨迹问题一致)。
| 沉淀位置 | 适合什么 |
|---|---|
| 会话 MEMORY | 个人习惯、本机路径 |
skills/ + workflows/ |
团队一致规则 |
tools/stage_gate.py |
必须 100% 执行的校验 |
推荐路径:多轮踩坑 → 离线归纳 → 人审 → 合并进 Skill/tools → rsync 到 Hermes profile。
7. Knowledge 与 Source Evidence 的边界
| 类型 | 例子 | 作用 |
|---|---|---|
| Source evidence | MR diff、缺陷单步骤、用户 curl | 证明「这次改了什么」 |
| Knowledge | 术语表、指标口径、页面说明 | 解释「业务上该怎样」 |
加载规则:
- 从
knowledge/_index.md(或领域子索引)出发。 - 只沿
related[].path跳转,禁止凭文件名瞎猜。 - 打开过的路径写入
knowledge_used——门禁检查 used,不是口头声称。
8. 案例对照:Bug #1649
8.1. 无 Harness
1 | 用户给 Bug ID + 「浏览器验证」 |
8.2. 有 Harness(阶段不可跳)
1 | 1. skill_view("agent-next") → index → bug-regression |
已写入 Router Pitfalls 的纪律:
- Bug Intake 没有 artifact,只有
notes[]。 - 用户说「浏览器验证」也不能跳过 Scope / Impact / Coverage / Decision。
- API 须从用户真实请求追踪;先确认产品线/版本(功能可能只存在于某一端)。
- 未确认不得 merge MR、force-push、切分支 push。
9. Cursor 与 Hermes 双端落地
| 载体 | 作用 |
|---|---|
仓库 AGENTS.md |
Cursor 自动注入 |
Hermes SOUL.md |
每会话注入;须手写 agent-next 硬规则 |
skills/ rsync 到 profile |
Hermes 侧 Skill 与仓库对齐 |
workflows/ 留在项目仓库 |
须在仓库根执行 phase_doc / stage_gate,或 cwd 指向仓库 |
常见坑:~/.hermes/profiles/coding/AGENTS.md 不会自动注入;规则可以写在 SOUL.md 或通过 skill_view("agent-next") 加载。
10. Skills 从「整本手册」到 Lazy Load:改造经验
本节记录 agent-next 在 dev 分支上的一次 Harness 瘦身:不是重写业务逻辑,而是把原先塞进 Router / 单体 workflow / 长篇 gate 散文里的规则,拆成可按阶段加载的文件,并用 phase_doc.py 让 Agent 不必猜路径。
10.1. 旧模式为什么撑不住
Lazy Load 之前,三类文档叠在一起,每轮会话都在抢上下文:
| 载体 | 旧形态 | 问题 |
|---|---|---|
Router skills/agent-next/SKILL.md |
~160 行,混有路由、阶段说明、踩坑 | Router 变「第二本 workflow」 |
| Workflow | 单体 workflows/bug-regression.md(~370 行) |
八阶段全文一次读入,后半段规则常被截断 |
workflows/stage-gates.md |
~630 行散文 + 表格 | Agent 重复通读;与 stage_gate.py 重复叙述 |
| 下游 Skill | Required Reading 指向单体 workflow | 阶段推进后仍引用已过期路径 |
体感症状与第 2 节 Bug #1649 一致:不是模型不会写用例,而是阶段表、gate 表、Pitfalls 在同一窗口里读不全,于是跳步、手写产物、路径写错。
10.2. 改造目标:三件事分开
| 职责 | 改造后放在哪 | 大约行数 |
|---|---|---|
| 指路(选 entry、声明读法) | Router + workflows/index.md |
Router ~70 行;index ~83 行 |
| 路由表(产物路径、阶段索引) | workflows/<entry>/README.md |
~55–65 行 / entry |
| 阶段动作(本步目标、Skill、Gate) | workflows/<entry>/phases/NN-*.md |
~15–35 行 / phase |
| 机器门禁 | stage-gates.md 机器表 + stage_gate.py |
gate 文档 ~174 行 |
哲学不变:Router 只调度,不写用例;阶段细节不进 Router;gate 以代码为准。
10.3. 我们实际做的四步(可复用顺序)
10.3.1. 拆 workflow:README + phases
以 bug-regression 为试点:
- 把 Deliverable Routing(
bug_surface→outputs/根目录、模板类型)留在README.md。 - 每个阶段一个
phases/NN-<slug>.md,统一小模板:
1 | 目标 / 输入 / 产出 |
README只保留阶段 索引表(阶段名 → 文件名),不展开步骤正文。- 删除单体
workflows/bug-regression.md等 stub,避免 Agent 继续read_file旧路径。
feature-testing、release-acceptance 按同一目录结构复制,保证三个 entry 形状一致。
10.3.2. 加解析器:phase_doc.py + phases.py
阶段名的权威列表只在 tools/phases.py 维护一份,与 stage_gate.py 共用——避免「文档写 Change Scope、代码认 Scope Change」类漂移。
1 | python3 tools/phase_doc.py --entry bug-regression --phase "Change Scope" |
Router 的 Required Reading 改为显式禁令:
不要在一轮里读完所有
phases/*.md;每阶段只phase_doc一次。
10.3.3. 瘦 Router,重 Pitfalls
skills/agent-next/SKILL.md 删掉可下放到 phase 的段落,只保留:
- 读序:
index→README(首次)→ 当前 phase →stage-gates机器段 run_state/skill_receipts/ 确认门禁- Pitfalls(从事故 offline 合并的纪律:Bug Intake 无 artifact、禁止跳步、API 须从用户 Network 追踪等)
事故教训 进 Pitfalls 或 tools,不进 phase 正文重复三遍。
10.3.4. 压缩 stage-gates.md
保留:Global Blocking Actions、Machine Rules By Phase 大表、与 PHASE_RULES 对齐的列。
删除或缩短:逐阶段散文复述(「本阶段要做 A、B、C…」已搬到 phases/*.md)。
Agent 侧约定:优先读机器表;全文仅在人类审计时需要。
10.4. 下游 Skill 怎么改
Lazy Load 后,下游 Skill 不再指向单体 workflow 文件,Required Reading 统一为:
1 | 1. phase_doc.py → 当前 phases/*.md |
以 epvs-test-cases 为例:把「读 workflows/bug-regression.md」改成「读 phase_doc 输出路径」。否则 Router 已 Lazy,下游仍拉整本旧 workflow,上下文节省被抵消。
run_state.py 默认把 state.workflow 设为 workflows/<entry>/README.md(不再是已删除的单体路径)——旧 state 不迁移会在 gate 或路径校验处暴露,属于 刻意的破坏式提醒。
10.5. 双端同步:仓库改完不等于 Agent 会用
| 动作 | 目的 |
|---|---|
rsync -a --delete skills/ ~/.hermes/profiles/coding/skills/ |
Hermes 侧 Router / 下游 Skill 与仓库一致 |
更新 SOUL.md 读法 |
写清 phase_doc、禁止跳步、Intake 前无副作用 |
| 新开 Hermes 会话 | 避免旧会话 MEMORY 仍引用 bug-regression.md |
跑 tests/test_phase_doc.py + 全量测试 |
阶段名、workflow 路径、gate 规则不散架 |
Cursor 侧依赖仓库 AGENTS.md 自动注入;改 workflow 目录结构后记得同步 AGENTS.md 里的路径示例。
10.6. 改造中的坑与验收信号
| 坑 | 现象 | 处理 |
|---|---|---|
| 旧路径幽灵 | File not found: .../bug-regression.md |
改读 README.md + phase_doc;清 Hermes MEMORY |
| Router 与 phase 重复 | 两处维护阶段表,改一处漏一处 | 阶段表只在 README 索引 + phases.py |
| 下游 Skill 未改 | 单阶段仍注入 300+ 行旧 workflow | 批量改 Required Reading 首条 |
| gate 散文复读 | 每阶段 Token 多 ~2.8K | 只读 Machine 表;见第 5.3 节对比 |
state.workflow 旧值 |
gate 或 validate 报 workflow 路径 | 用 run_state 重写或新建 run-id |
验收 Lazy Load 是否生效(与机器门禁同等重要):
- 每个阶段日志里 仅一次
phase_doc.py,且只read_file一个phases/*.md - 首轮不出现「连续读取 8 个 phase 文件」
state.workflow形如workflows/bug-regression/README.md- Router 行数稳定在 ~70 行量级;单体 workflow 文件在仓库中 不存在
10.7. 量化收益(Bug 回归 @ Change Scope)
| 读法 | 约 Markdown 行数 |
|---|---|
| 旧:单体 workflow + 长篇 gate 散文 + 胖 Router | 400+ |
| 新:README + 单 phase + gate 机器段 + 瘦 Router | ~100 |
整单八阶段规则类 Token 约 16K–17K(推荐读法),相对旧 Harness 规则部分约省 一半;估算口径与第 5.3 节一致。
10.8. 给其他团队的一句话建议
若你已在用「一个大 Skill + 长 workflow」,不要先加 Prompt,先问:
- 阶段能否 一文件一阶段?
- 路径能否 机器解析(
phase_doc或等价物)? - Router 能否瘦到 只指路 + Pitfalls?
- gate 能否 表格 + 脚本,散文是否可删?
四问都能答「是」,再改下游 Skill 的 Required Reading 并做一次 故意删除旧 stub 的破坏性发布——逼 Agent 和新会话走新路径。Lazy Load 的价值不在少写几百行 Markdown,而在 让「当前阶段该读什么」变成可执行、可审计的单次动作。
11. 结语
回到开篇那个矛盾:测试 Agent 往往写得出来,却不敢直接用。差距通常不在模型能力,而在 过程能否被检查、复现和阻断副作用。agent-next 把这件事做成仓库里的固定结构——模型可替换,Harness 留在 Git 里当团队资产。
它的分工一句话说清:
Router 指路,Workflow 定阶段,Skill 承载专长,Knowledge 解释领域,Tool 执行门禁。
特性测试、Bug 回归、发布验收共用同一套五层目录;差别只在 workflows/index.md 选哪个 entry、当前 phase 对应哪一篇 phases/*.md。一次合规推进,至少经过这条链:index 选路 → phase_doc.py 读本阶段 → 按阶段加载 Skill 并登记 skill_receipts[] → copy_template.py 写入 outputs/ → validate_* 与 stage_gate.py 裁决能否进入下一阶段。Router 不写用例、不上传缺陷、不跑自动化;stage_gate.py 失败即停,不猜、不跳步。
Lazy Load 是上述结构的默认读法:每轮只展开当前阶段那一篇 phase 文档,门禁以脚本为准。整本 workflow 塞进一轮,规则读不全,Harness 就等于没起作用。纪律也不靠聊天记忆——踩坑经人审后写入 Skill Pitfalls 与 tools/,会话 MEMORY 只留个人习惯。
若要在其他业务复用,fork test-agent-next(dev 分支),替换 knowledge/ 与 workflow 表头;建议保留 runs/ 与 outputs/ 分离、copy_template、validate 与 gate 这一套。换领域不换骨架,换模型不必重搭流程。


