从Notion迁移到Obsidian后,我如何用Codex Skills重构知识管理

过去五年我一直都在重度使用 Notion。它让我快速搭好了资料库、任务库、项目页,习惯养成库,早期效率非常高。但进入 AI 时代之后,我越来越频繁地遇到几个现实问题:
- Notion 的数据模型偏平台内闭环,导出可以做,但很难做到“长期无平台依赖”的工作方式。
- AI 能力可用,但很多高频能力需要额外付费,且工作流可定制深度有限。
- 我想做更细粒度的自动化时,经常要绕着产品边界走,最后还是回到大量手工操作。
这也是我这两年来决定将知识库管理迁移到 Obsidian 的原因。对我来说,意义主要在三点:
- 本地化存储。知识是 Markdown 文件,不是平台对象,备份、迁移、版本管理都更可控。
- 可自定义 AI。AI 不再只是“问答入口”,而是可以和我的知识库状态联动,跑固定流程。
- 插件生态丰富。Obsidian 允许我把“记笔记”变成“可执行流水线”。
迁移之后我做的第一件事就是重构流程。我把自己的学习与沉淀链路拆成 4 个 Codex skill:
clipping-updatedaily-learningstudy-outlinestudy-quiz
1. 我在 Notion 阶段踩过的坑
我之前有个很典型的问题: 收藏很多、阅读很多、真正沉淀很少。
具体表现是:
- 同一主题的文章,格式差异巨大,后续检索和复盘成本很高。
- “今天该学什么”靠临时决定,忙起来就断档。
- 学完后很少留下结构化产物,下次还是从头读。
所以我给自己定了一个原则: 知识管理不能依赖意志力,要依赖可重复执行的系统。
2. 我现在怎么管理 Obsidian 里的文章知识库
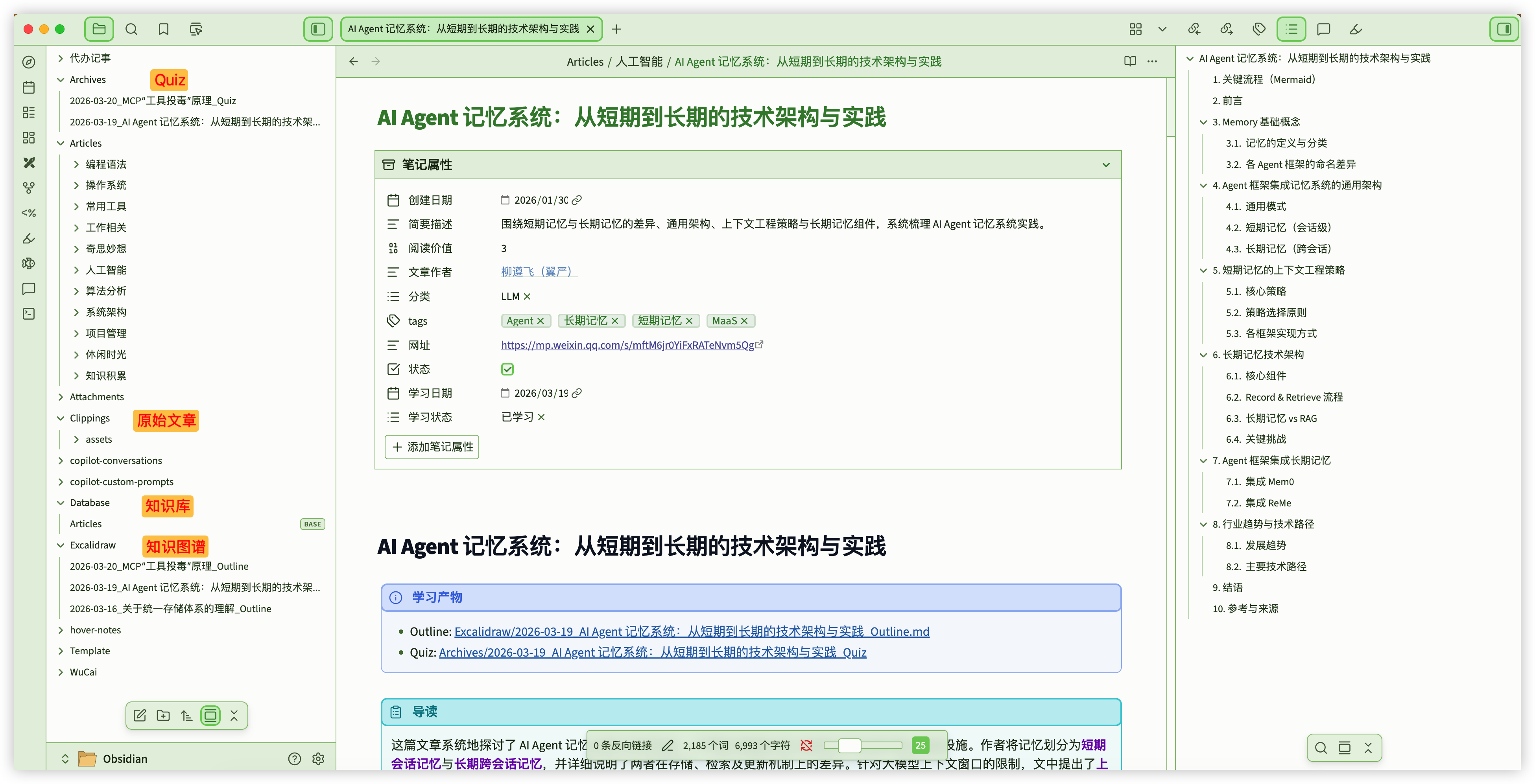
我把 Obsidian 知识库拆成三层:
- 数据层: 所有文章是本地 Markdown 文件。
- 状态层: frontmatter 中用
学习状态、学习日期做调度信号。 - 执行层: 用 Codex skills 负责每一步固定动作。
这样做以后,我每天只需要推进状态,不需要重新设计流程。
3. 四个 Skills 的闭环
1 | flowchart TB |
3.1. clipping-update: 把入口质量先拉齐
我习惯通过RSS订阅不同的文章,然后使用Obsidian Web Clipping插件将想要精读的文章保存到Obsidian的Clipping文件夹中。但是经常会碰到抓取保存后格式错乱的文章,如果自己编辑的话就会浪费很多不必要的时间。现在,我会让clipping-update帮我格式化文章。我只需要在codex中执行$clipping-update,它就会先帮我处理 Clippings 中最新一篇,主要是做三件事:
- 正文结构规范化(标题、列表、表格、代码块、空白)
- 必要时插入
Tip阅读任务 callout - 重写 metadata(
简要描述、分类、tags、状态等)
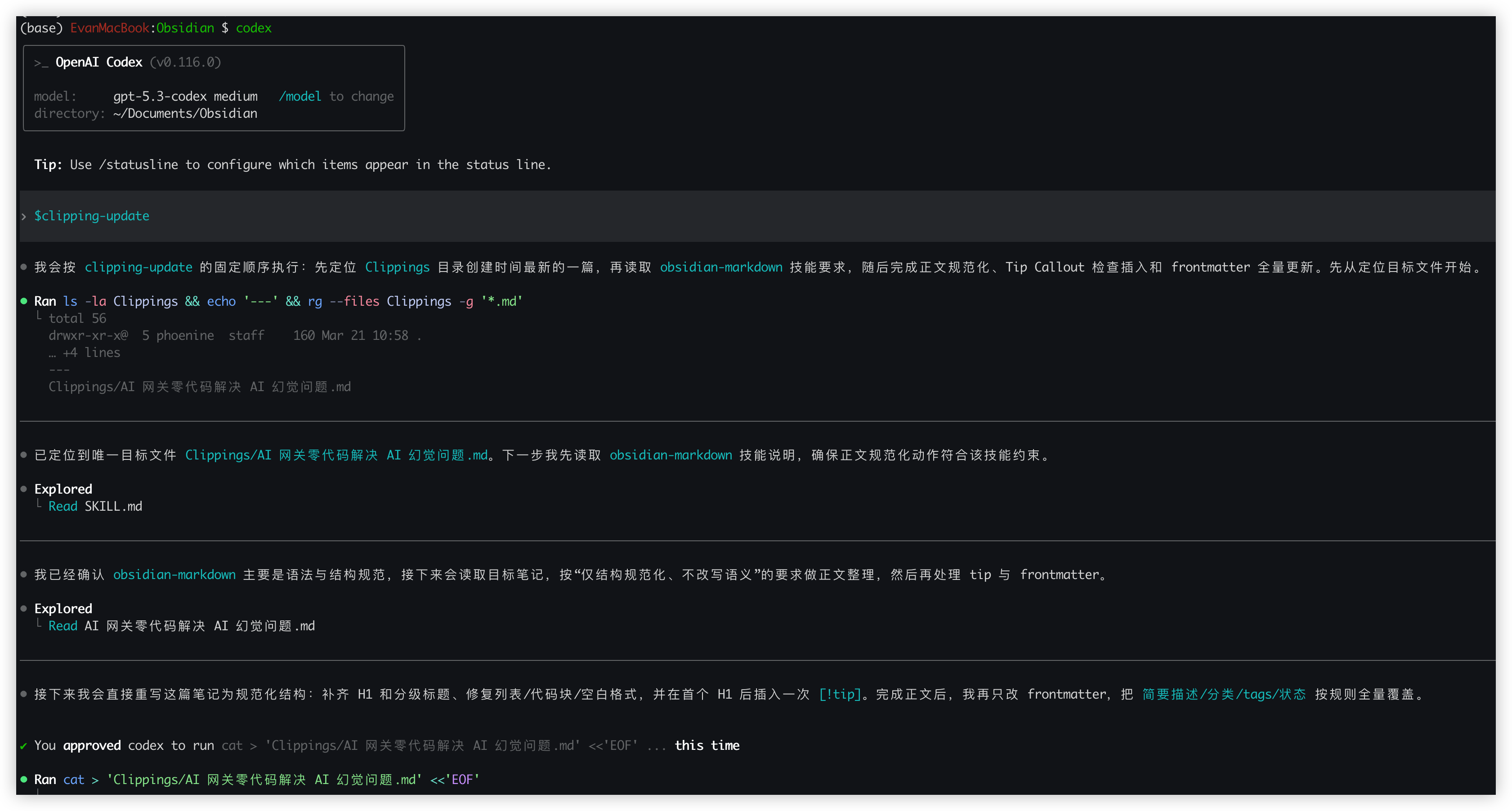
这一步本质上是“数据清洗”,保证后面的步骤吃到的是结构化输入。
3.2. daily-learning: 自动启动当日学习
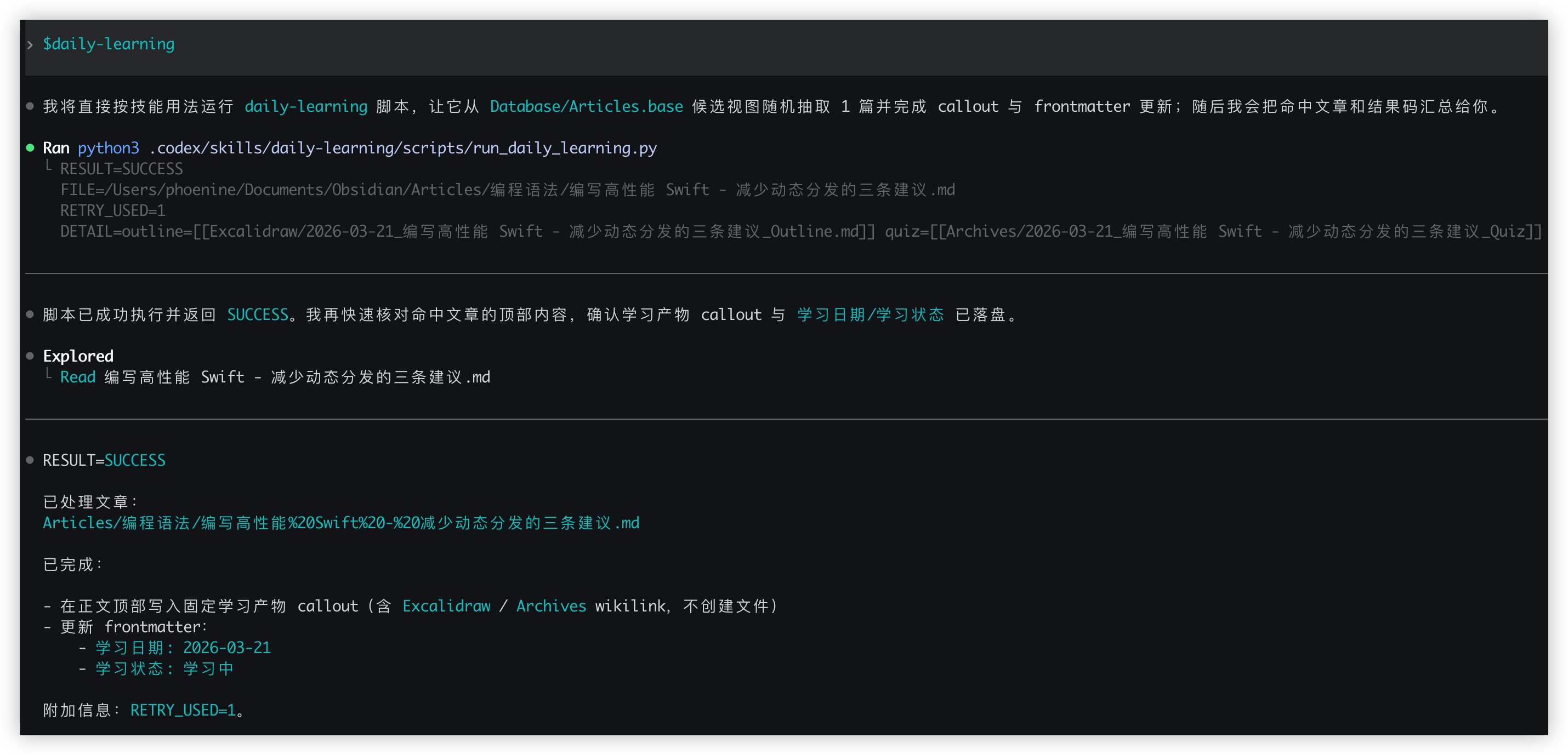
这个 skill 会从 Database/Articles.base 的“学习候选”视图随机抽 1 篇,命中后会:
- 在正文顶部插入固定
学习产物callout - 只创建链接,不提前创建实体文件
- 更新 frontmatter:
学习日期=今天,学习状态=学习中
我之所以这么设计,是因为我发现学习流程最容易断在“启动阶段”。如果每天都要自己挑文章、建链接、改状态,哪怕每步只花几分钟,累计起来也会变成一种心理负担,最后就很容易拖延。
所以 daily-learning 的目标不是“聪明推荐”,而是“低阻力启动”:
- 随机抽取候选,减少“今天学哪篇”的决策消耗。
- 只做最小必要写入,执行快、失败面小。
- 先把学习产物入口挂好,再交给后续 skill 接力生成内容。
它对我最有用的两个“防故障”设计是:
- 如果文章已存在学习产物 callout,会跳过并重抽,保证幂等。
- 重抽有上限,最多
min(候选池, 20),避免无限循环。
带来的好处很实际:
- 我几乎不再卡在“开始学习”这一步,日常执行更稳定。
- 每篇被选中的文章都会自动挂上 Outline/Quiz 入口,后续动作不容易丢。
- 状态统一更新后,
study-outline与study-quiz能无缝衔接,流程真正形成闭环。
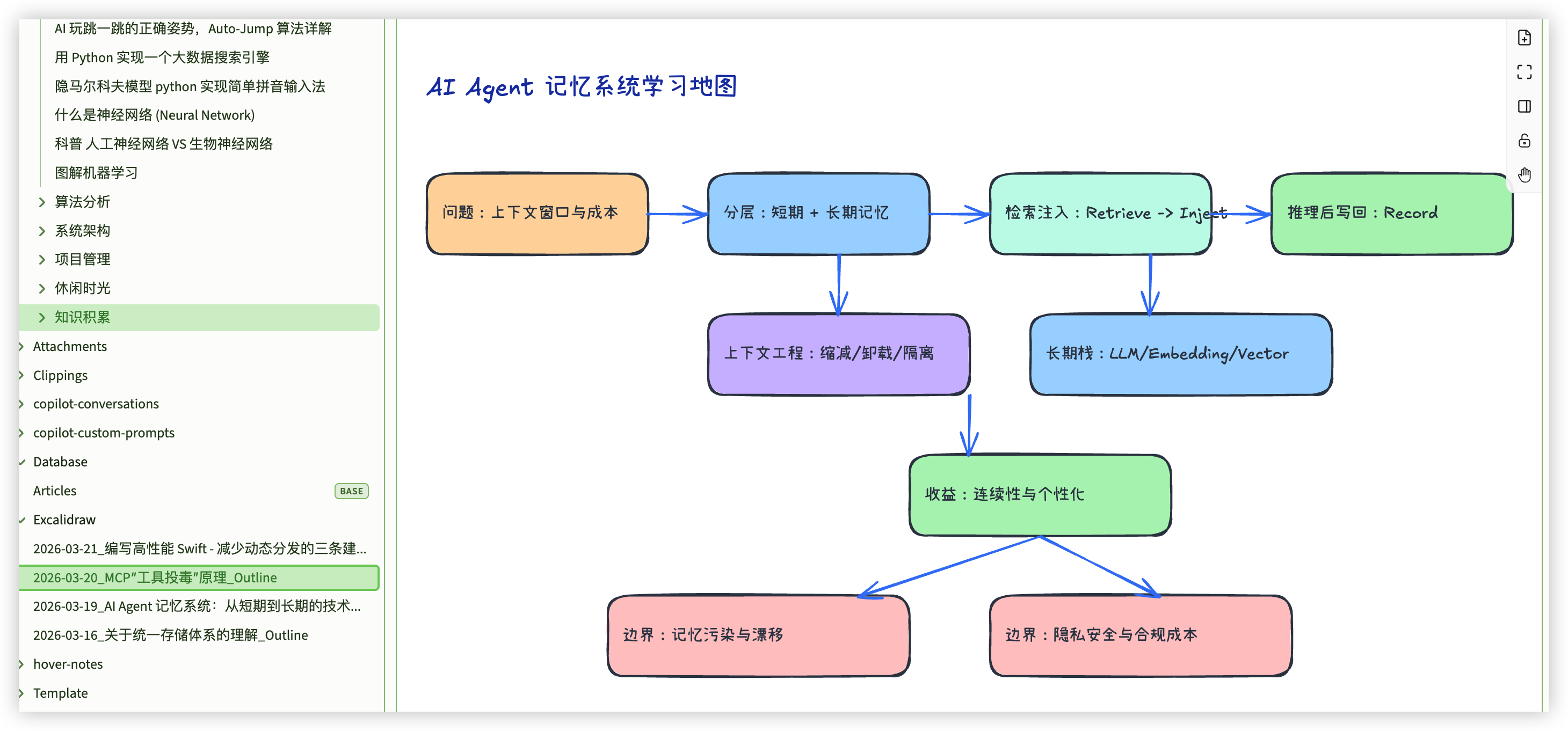
3.3. study-outline: 用图谱逼出结构化理解
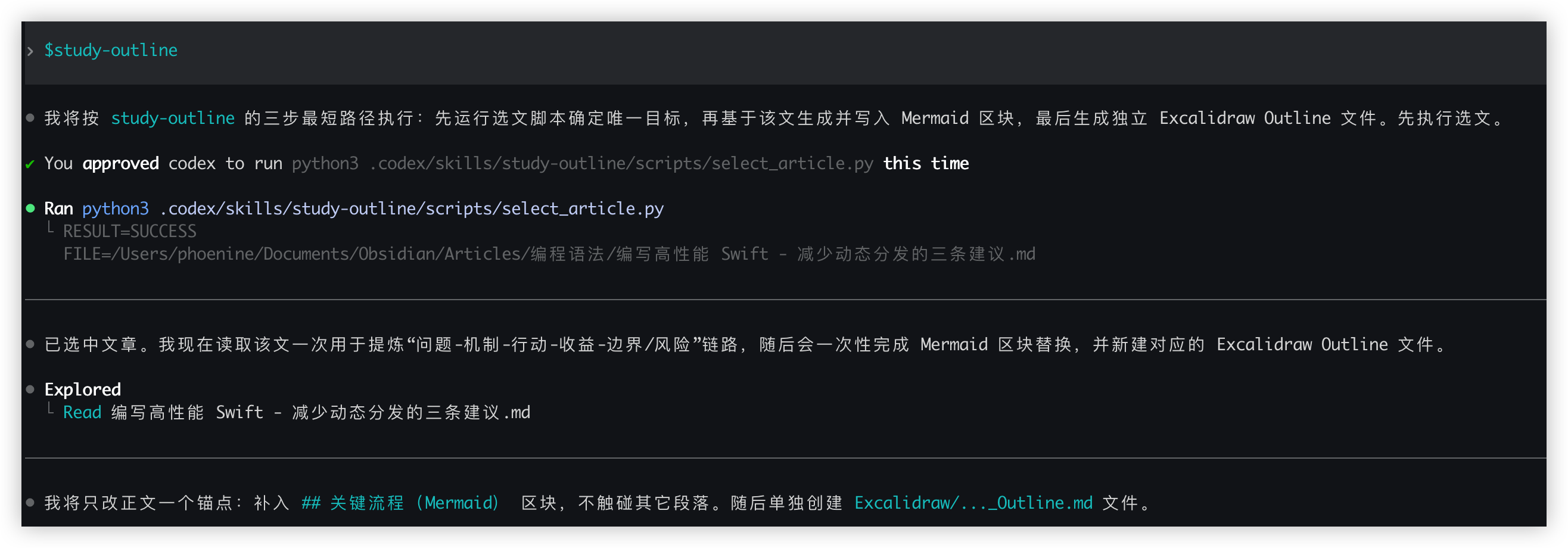
这个 skill 只处理 学习状态 == 学习中 的文章,产出两类结果:
- 正文中的
## 关键流程(Mermaid)区块 Excalidraw/YYYY-MM-DD_文章标题_Outline.md独立学习地图
我为什么坚持做“双图产物”,核心是把“读懂”变成可检验动作:
- Mermaid 负责线性表达: 问题、机制、步骤、边界,一眼能复述主链路。
- Excalidraw 负责空间表达: 概念关系、证据与质疑、风险与行动,适合做跨文章对照。
这个 skill 的约束我也刻意设得很硬:
- 只改正文一个锚点区块,不触碰其他段落,避免污染原文。
- 图谱独立落到
Excalidraw文件,和文章正文解耦,便于长期复用。
带来的好处是:
- 我复盘时不再从头读全文,先看图就能快速恢复上下文。
- 同主题文章可以在 Excalidraw 层做横向拼接,沉淀成自己的认知地图。
- 后续做
study-quiz时,题目质量会更稳定,因为输入已经被结构化了。
3.4. study-quiz: 把理解变成可验证能力
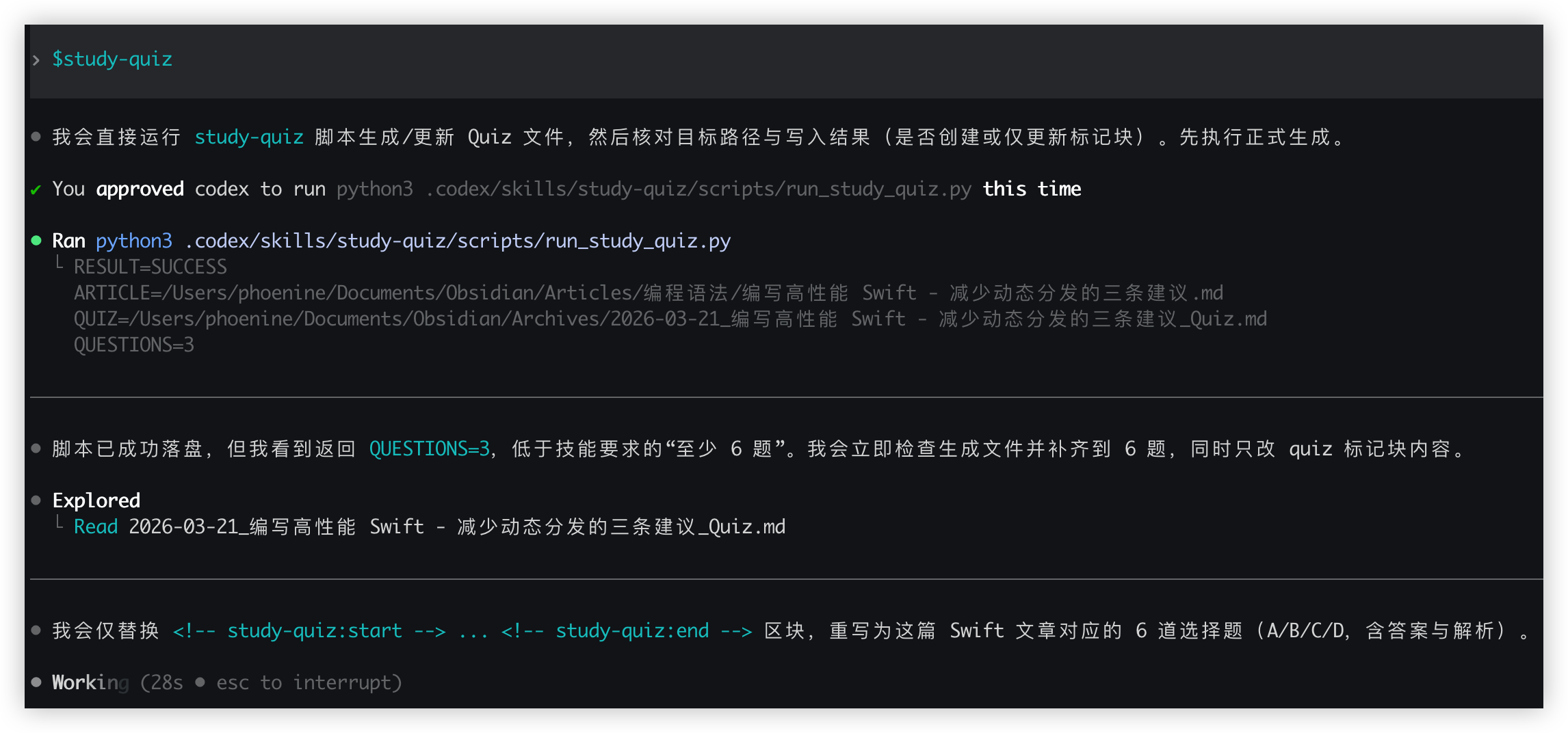
这个 skill 会生成或更新:
Archives/YYYY-MM-DD_文章标题_Quiz.md
我做这一步的原因很现实: 只做笔记很容易产生“理解错觉”。当你能复述,不代表你能区分关键概念;当你能看懂,不代表你能迁移到新问题。
所以 study-quiz 我坚持三个设计点:
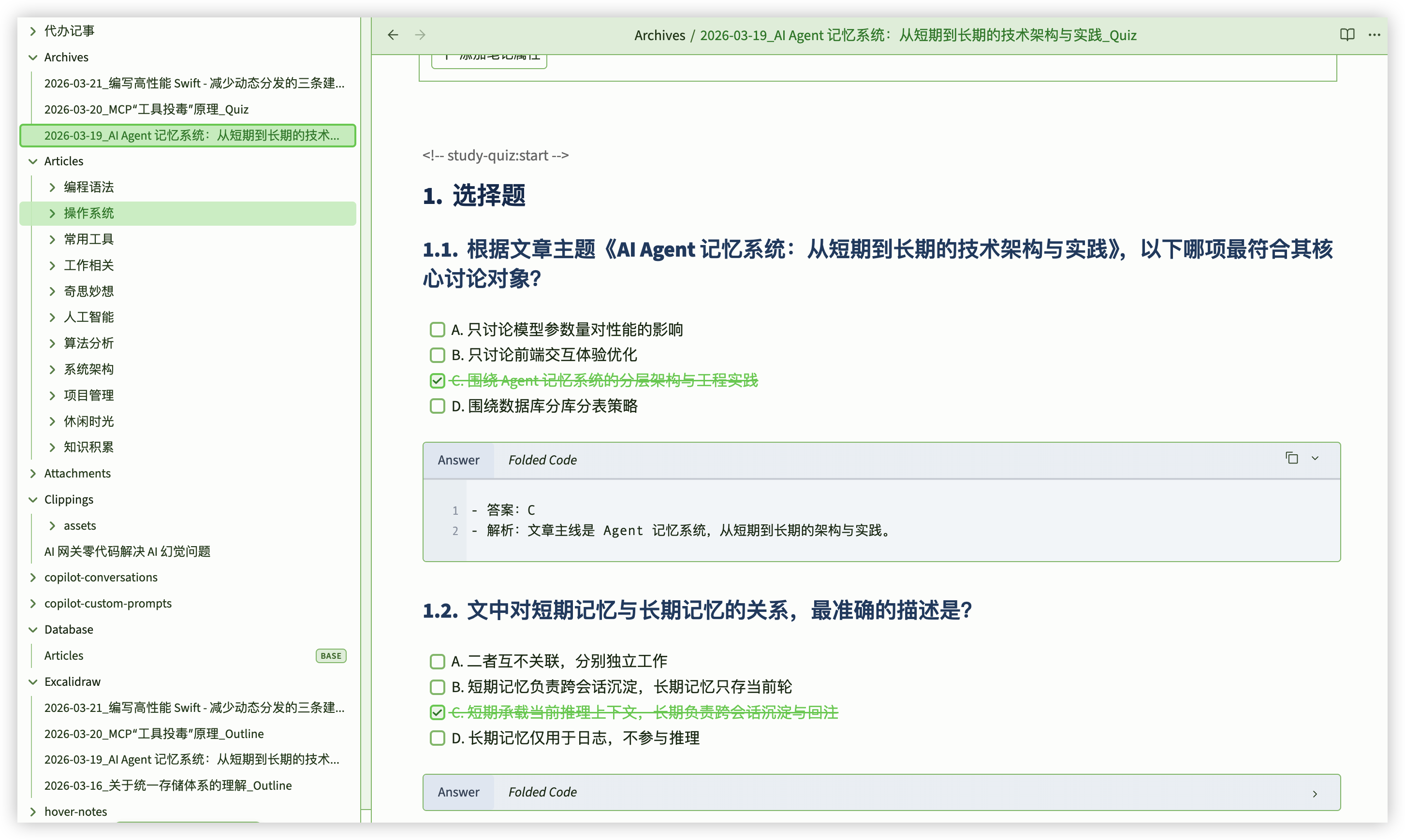
- 题型固定为选择题,至少 6 题,每题都要有题干、选项、答案、解析,确保可快速自测。
- 如果 Quiz 已存在,只更新
<!-- study-quiz:start --> ... <!-- study-quiz:end -->标记块,不整篇覆盖,避免把我手写补充内容冲掉。 - Quiz 文件按日期和文章标题落盘,和学习状态对应,方便回看一段时间内的学习质量。
它带来的好处是:
- 我能很快发现“看起来懂”和“真正掌握”之间的差距。
- 题目和解析会倒逼我补足概念边界,避免只记结论不懂机制。
- 长期看,
Archives会沉淀成可复用的训练题库,新主题也可以拿旧题做横向对比。
4. 我平时怎么跑这套流程
我的日常节奏基本是:
- 新文章进
Clippings,先跑clipping-update做标准化。 - 每天执行一次
daily-learning,自动选当天学习目标。 - 学完后跑
study-outline,把理解画成 Mermaid + Excalidraw。 - 最后跑
study-quiz,把理解转成可测验题库。
时间久了我发现,自己不再是“收集很多链接的人”,而是“持续产出可复用知识资产的人”。
5. 结语
如果你也在从 Notion 迁移到 Obsidian,我的建议是: 先别急着做完美结构,先做一个能每天跑起来的最小闭环。AI 时代最稀缺的不是工具功能,而是你能否持续把信息变成自己的认知资产。